EmotionNAL: From Facial Expression To Sound
Cross-Modal,
Digital Music, MAX/MSP,
Interactive Installation
Can a facial expression have its sound?
What does one’s face sound like?
How to represent the process when I look into people's face by sound?
“EmotionNAL” is a camera-based installation that captures participants’ faces in front of the camera and generate sounds with respect to that.
It combines facial expression detection, emotion detection, signal processing, and sound mixing technologies.
This work explores the potential of connecting facial expressions and sound together, constructing a creative method to interact with music and explore how different facial expressions and emotions can affect the sound.
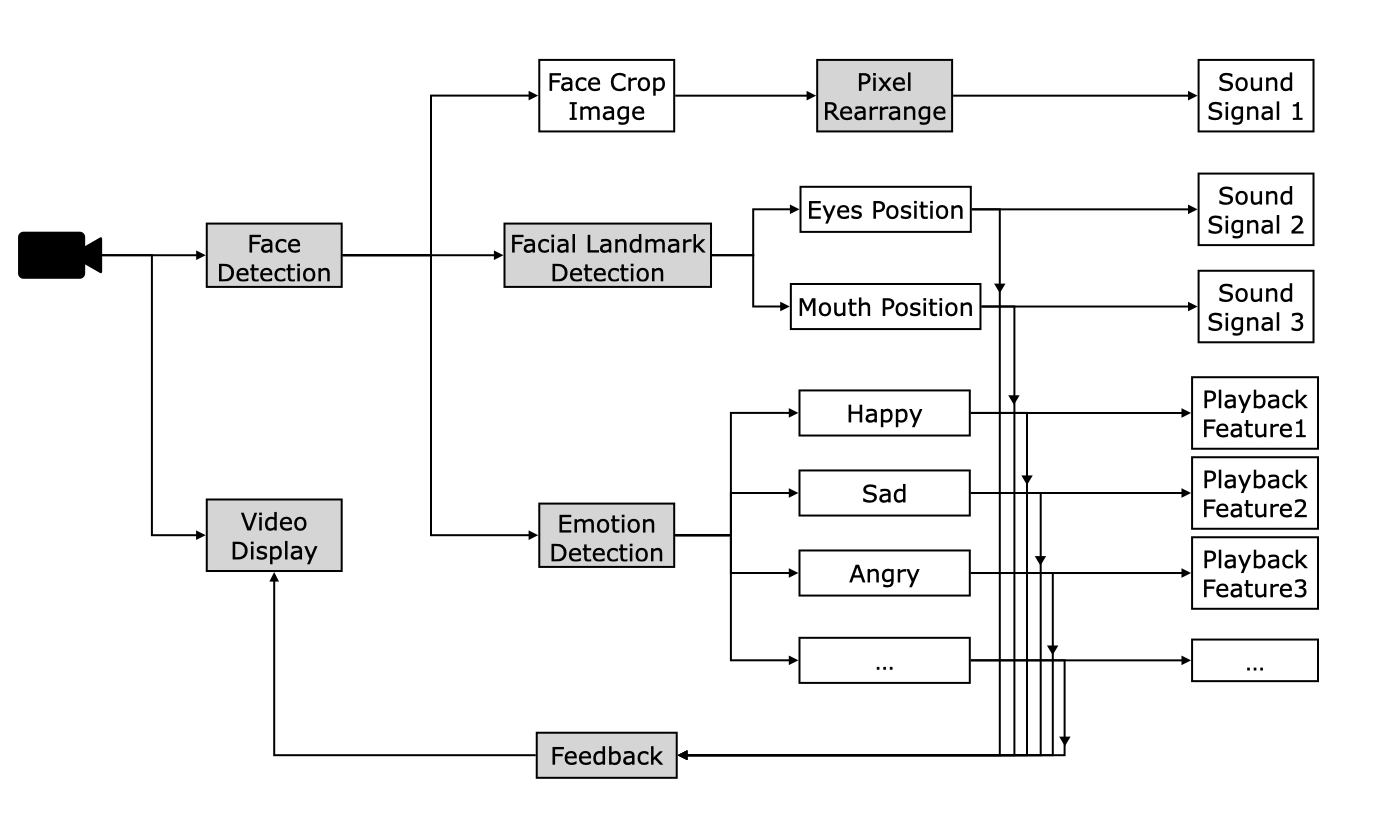
There are three steps of recognizing one frame of the audience's face: an overall impression of the whole face, the expression of the face, and the emotion behide the expression. "EmotionNAL" follows this order to process one frame of captured vide.
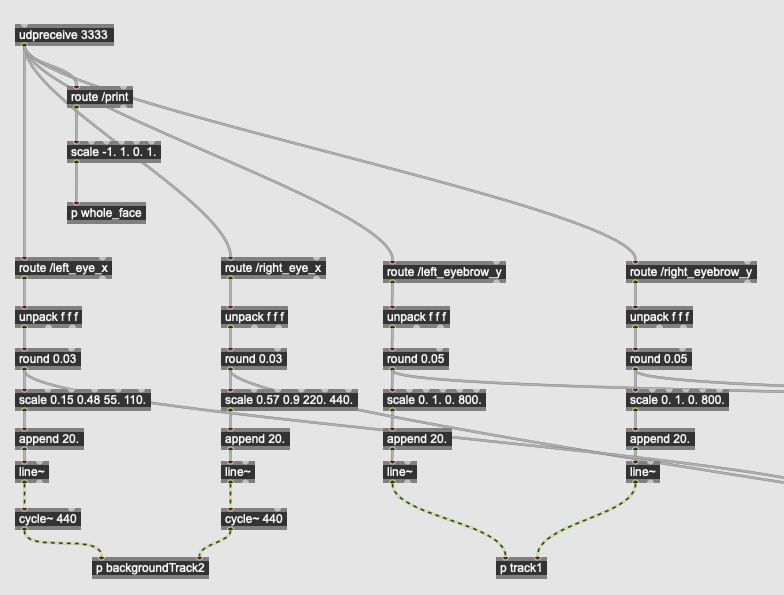
The program first conducts facial detection by each frame to the video captured by the camera. The captured face bounding-box will be transformed directly to a sound signal after the pixel rearrangement that convert 2D image to 1D array.
The program then computes the facial landmark of the detected face bounding-box as facial expression. The eyes position and mouth position will be converted to sound signal by controlling the cycle~ module.
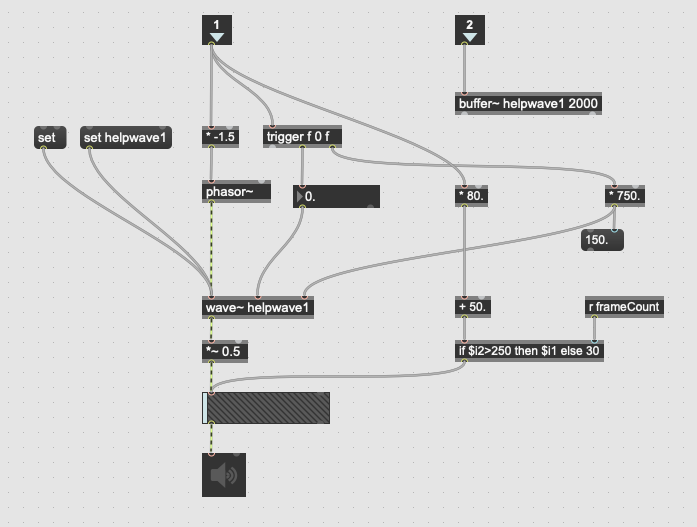
The emotion detection module is conducted then. The program computes each emotion's (happy, angry, sad, surprised, fealful, disgusted, netural) likelihood of one expression. The computed likelihood values control the playback parameters of the sound track.
The program is built with Python (3.8).
- Face (Landmark) Detection: link here
- Emotion Detection: link here
- Visual and Sound Generation: MAX/MSP, Vizzie